Tripleodeon
Closing The Gap Between Your Users And Their Data
In September, I was lucky enough to speak about local-first apps at the International JavaScript Conference.

Local-first apps are a topic very close to my heart! Here are the slides and (tweet-shaped) notes I presented.
If you’d like to comment on individual slides, there’s a Twitter thread here. Enjoy!

A few months ago, I left Meta and my professional life in Silicon Valley, and started on a new adventure: living with my wife on a sail boat, Scout.
Here we are, anchored by Coney Island so I could get to this conference.

It’s not every day you downsize onto a boat. One thing I did was archive my digital footprint before I moved onboard.
To do so, I categorized my local files by date and I copied them over, year-by-year, to the archive.
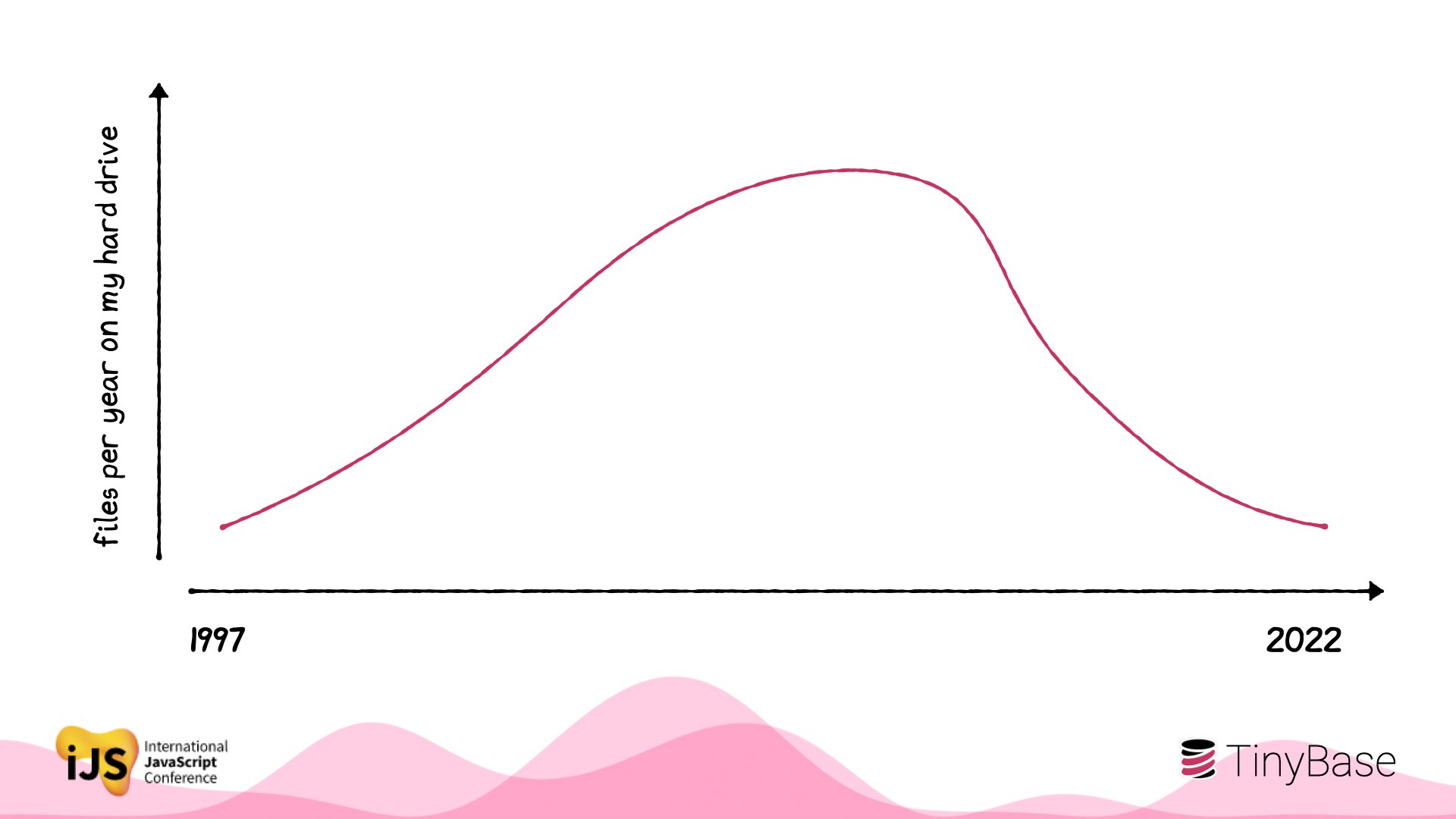
I noticed a very interesting thing.
During the 2000s, I had more local artifacts every year. But around 2010, the archiving accelerated: fewer files each year.
By 2021, I barely had anything to show for myself!
It’s like my work just wasn’t on my computer…

And of course, that’s exactly what had happened.
My mail isn’t in .pst files any more. My photos aren’t on my hard drive. Most of my code isn’t on my laptop.
Documents, spreadsheets, designs, sketches, presentations: they’re all on someone else’s computer now.
(Sticker credit @chriswatterston)

Now, after a decade, we maybe take this for granted. But it is actually pretty cool.
I can drop my laptop in the sea and it’s probably OK. Everything important is saved on a quietly humming computer in a rack in a Google, or Apple, or Amazon data center.

And of course, it’s easier than ever to work together: we don’t have to send files back and forwards over email with increasingly ridiculous names to collaborate.
All you need is that fast internet connection!
Well, I don’t have time to talk about life on a boat, but let me at least say that this is a regular sight for me. I’ve become very aware of how dependent I am on other people’s computers.
And it’s made me think about the shift that’s happened over the last decade.

Once, our devices were everything. Our electronic destiny was in our own hands. When we built apps, they were ‘local-first’: state was always stored on the user’s computer.
The web was a useful to share and consume, but not fundamental to daily creative workflows.

Now, the pendulum has swung hard the other way. ‘Cloud-first’ intelligence, data, and business logic is nearly always hosted elsewhere.
And, our devices, which aren’t just desktop computers of course, act as thinner and dumber clients, entirely beholden to connectivity.
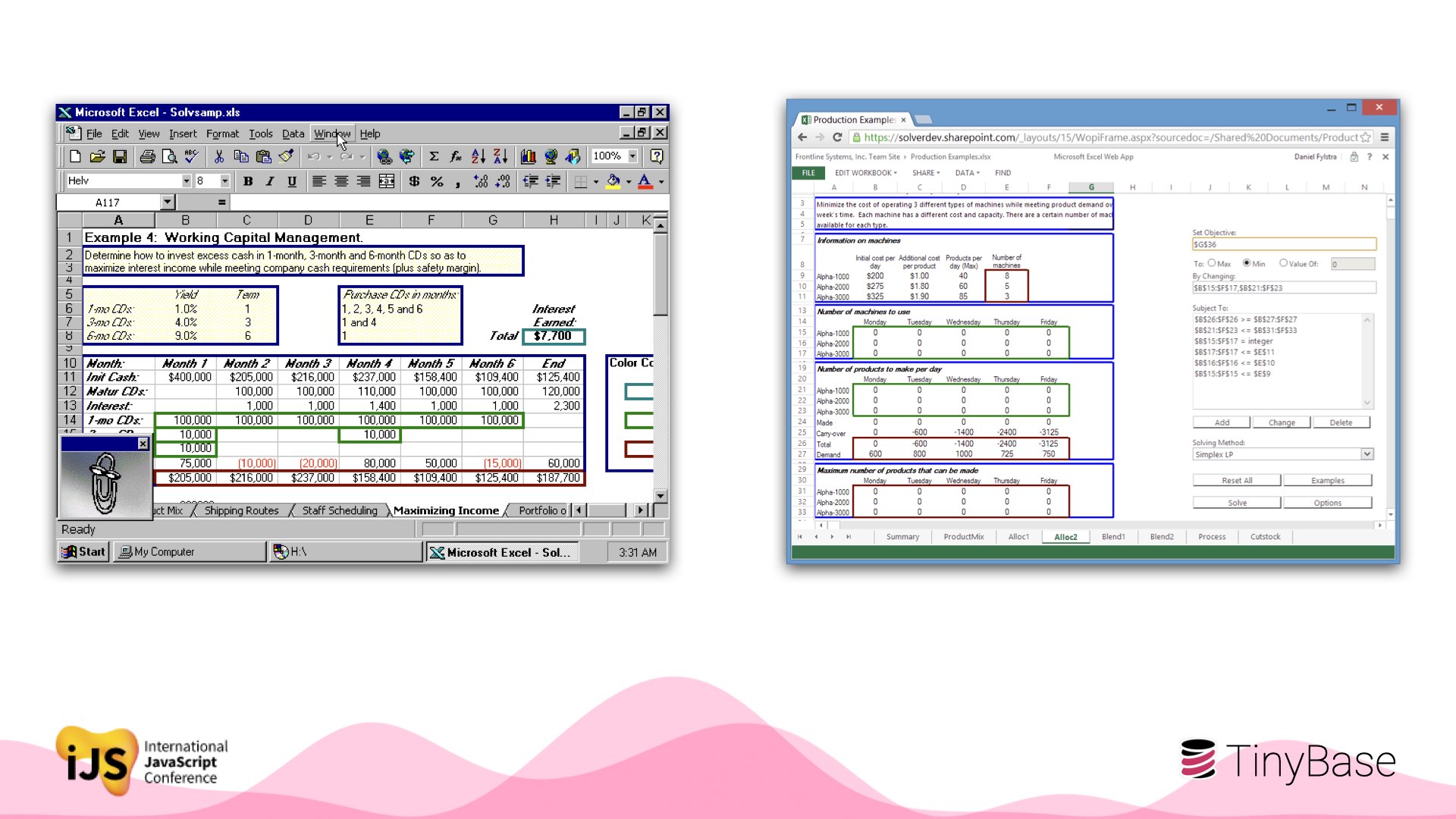
Despite this huge architectural shift, apps and their user experiences haven’t often changed that much. Cloud-first Excel in 2022 looks a lot like local-first Excel in 1997!
So has it been worth it? I do wonder if we’ve lost some trade-offs as this pendulum has swung.
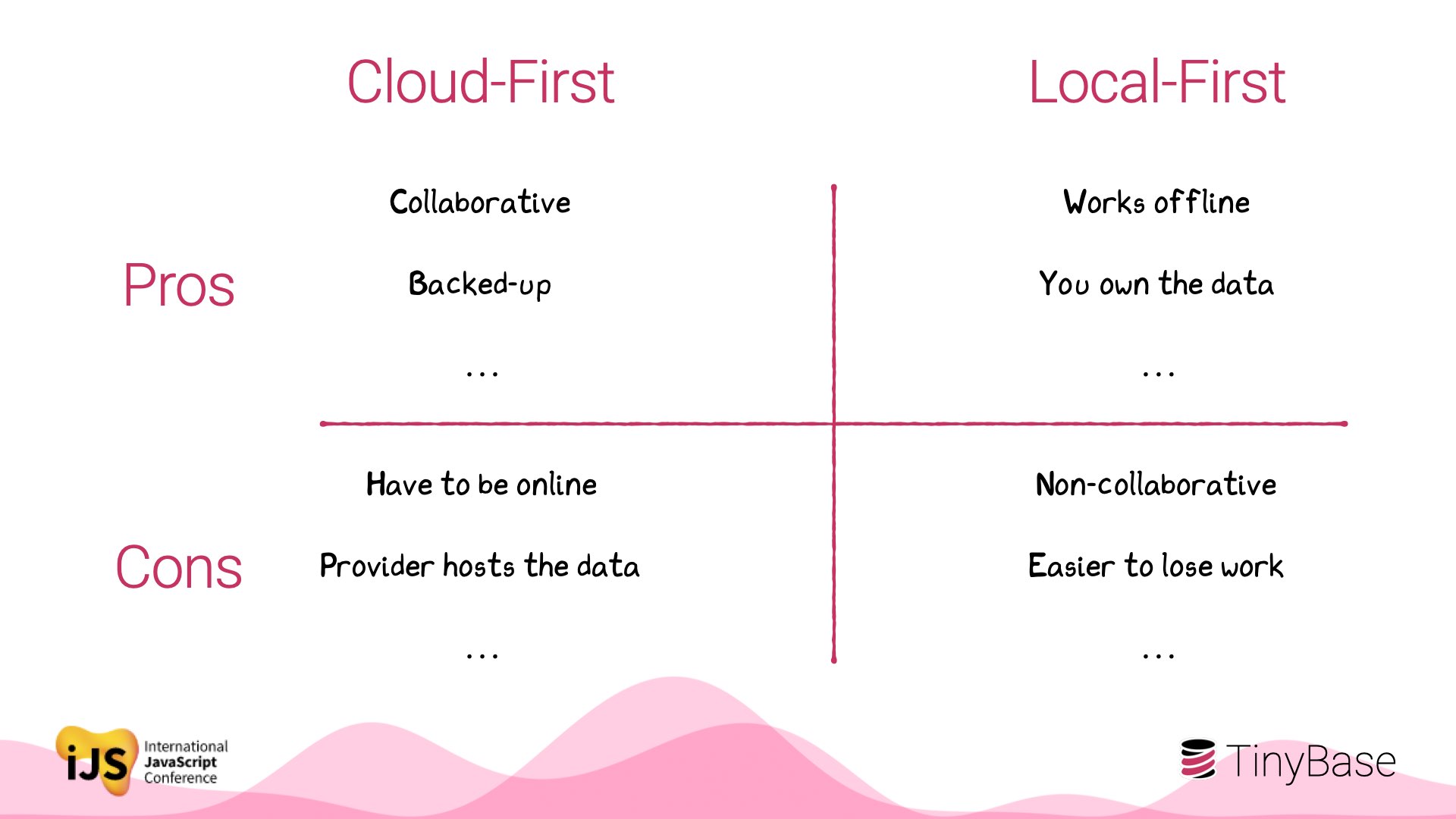
Pseudo management consultancy! The pros and cons for the two approaches go on and on. It would be awesome if we could figure out the best of both worlds.
But honestly, when it comes to experience, what really separates a cloud first app from a local first app?

Now maybe I have rose-tinted nostalgia, but spinners seemed rare in the 90s.
Now? You’ll spin whenever you need data that isn’t present on your device. Which, with a cloud-first app, is… all of it.
Even well-written cloud-first apps are competing with the speed of light.

At least spinners are educational I suppose.
They’re reminding us that your embattled app developer is having to fight the laws of physics to get YOUR data onto YOUR computer.
So let’s think about this from a developer perspective.
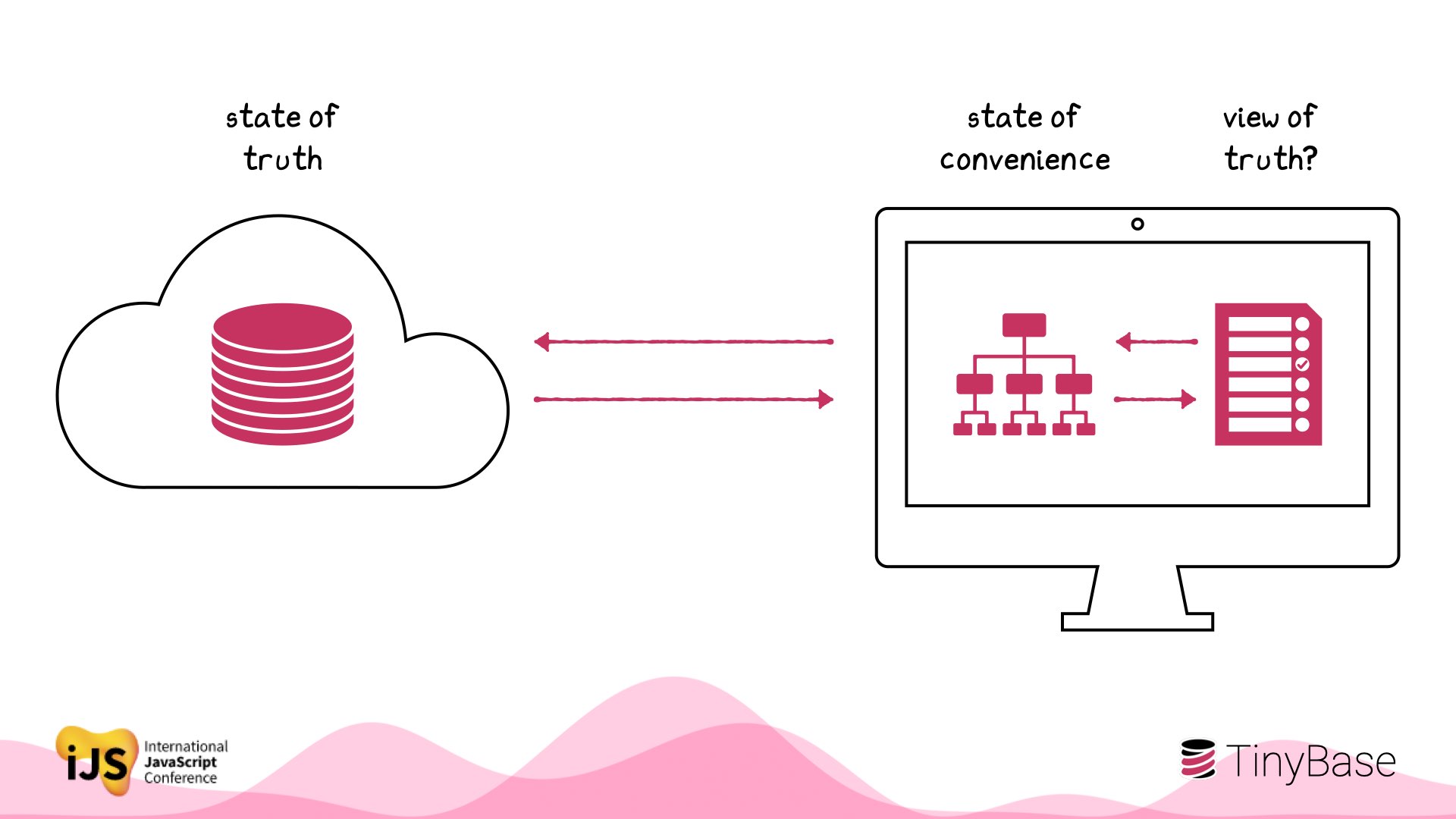
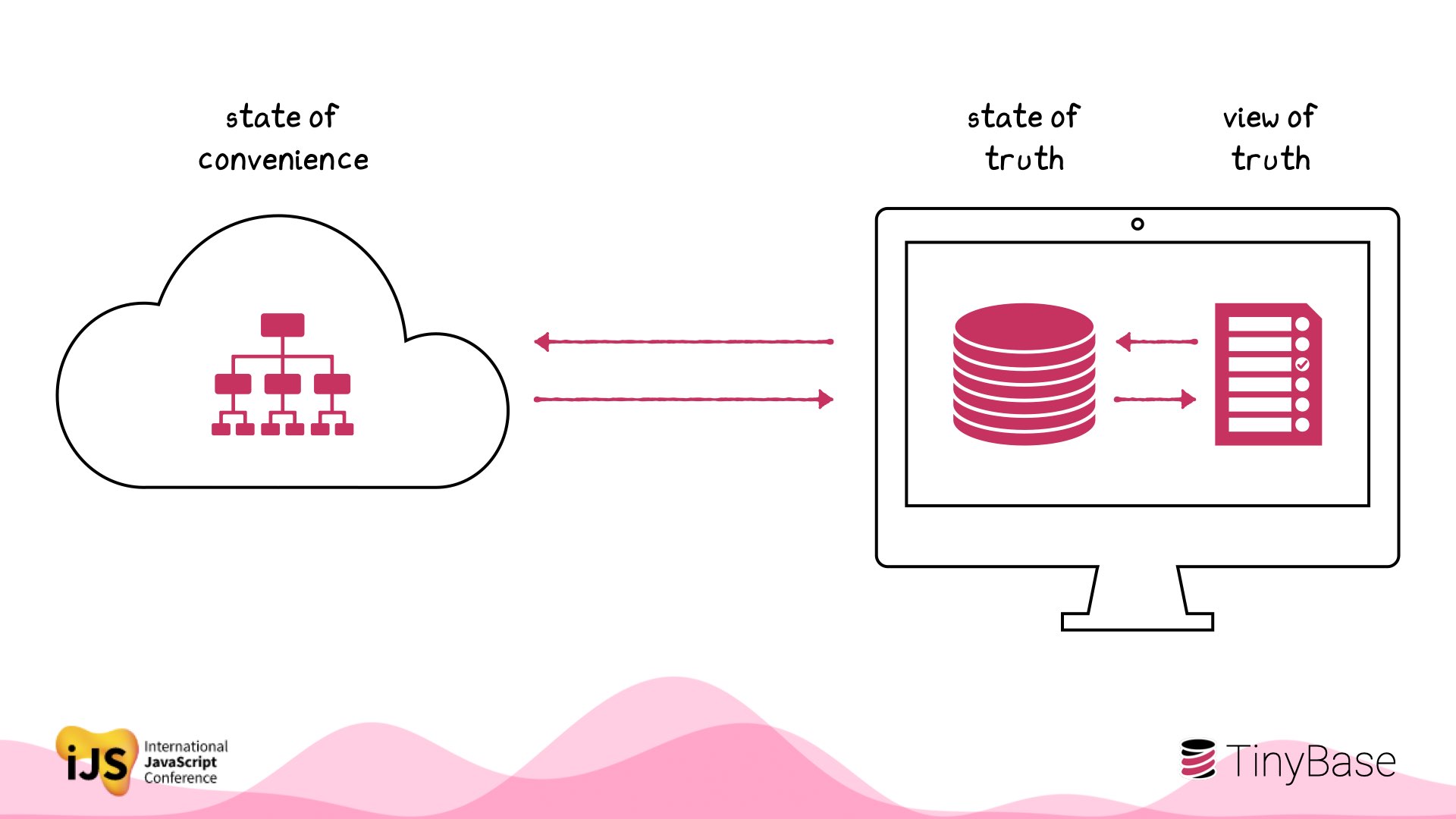
This is how we architect web apps by default today.
But there’s a challenge here. The user thinks they’re seeing ‘the view of truth’, not the view of your app’s local cache. In fact the state of truth and the supposed view of truth are a long way away from each other.

PULL data every time there’s a new view.
POLL for changes in case something happened on the server.
Oh, the user makes a change? Get the change back to the server somehow, and reconcile.
PRAY that the resulting local state is consistent.
Sigh. Is there another way?

What happens when we think local-first? What if local state is the source of truth?
Immediately the state and view of truth are right next to each other. For a start, you can now keep them in sync at 16ms or less!
We can also make the state more structured on the client.
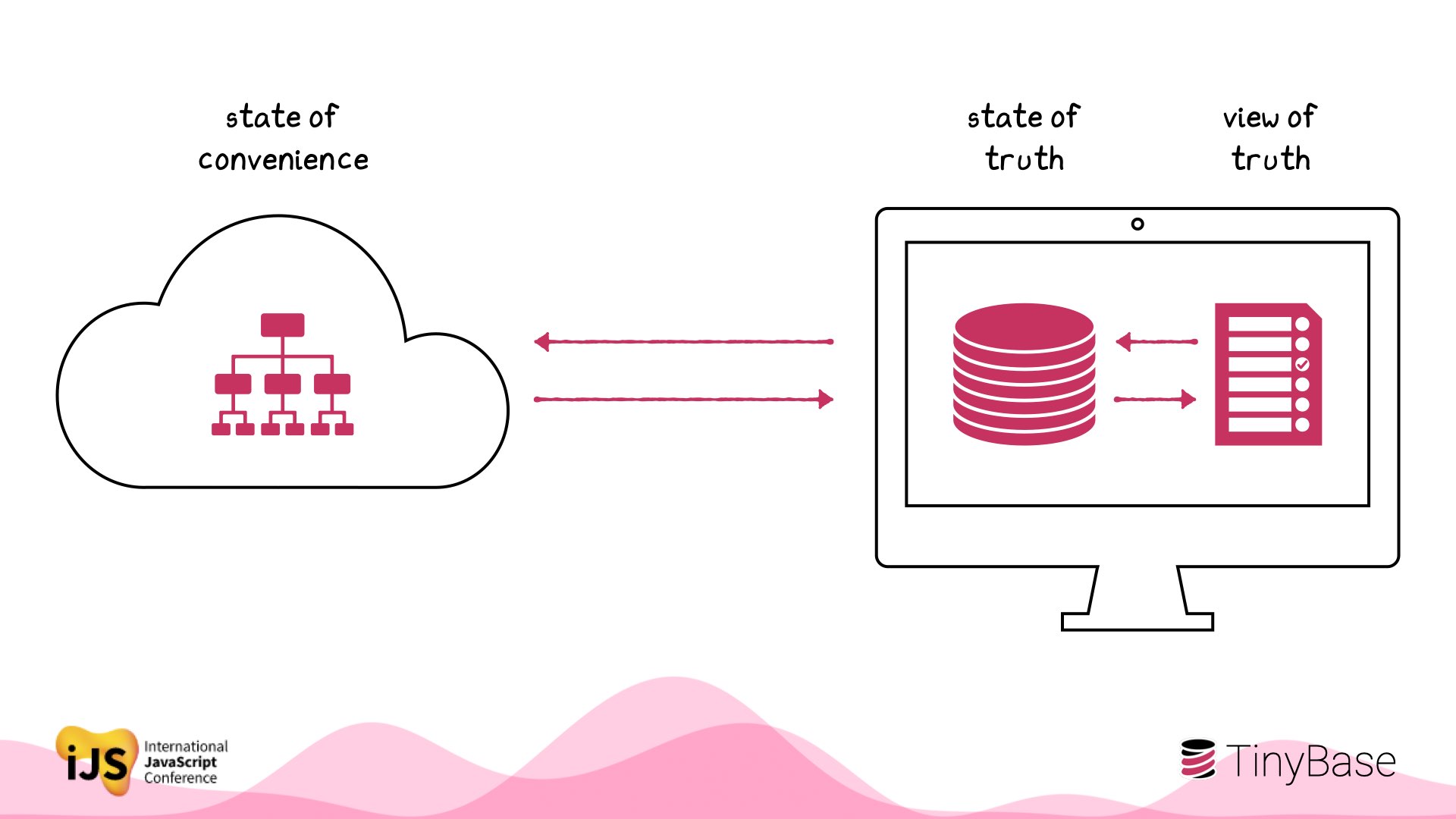
You’re closing the gap between your users and their data.
And local-first isn’t local-only. There’s nothing to stop us persisting that data to the cloud.
But that’s at our convenience: perhaps to save a snapshot every now and then, rather than on the critical UI path.

This was a super essay from four folks at MIT (@geoffreylitt, @nschiefer et al), exploring this idea.
This quote in particular jumped out. Not only can we provide a better experience for users, but it might also be easier to build these apps ourselves!
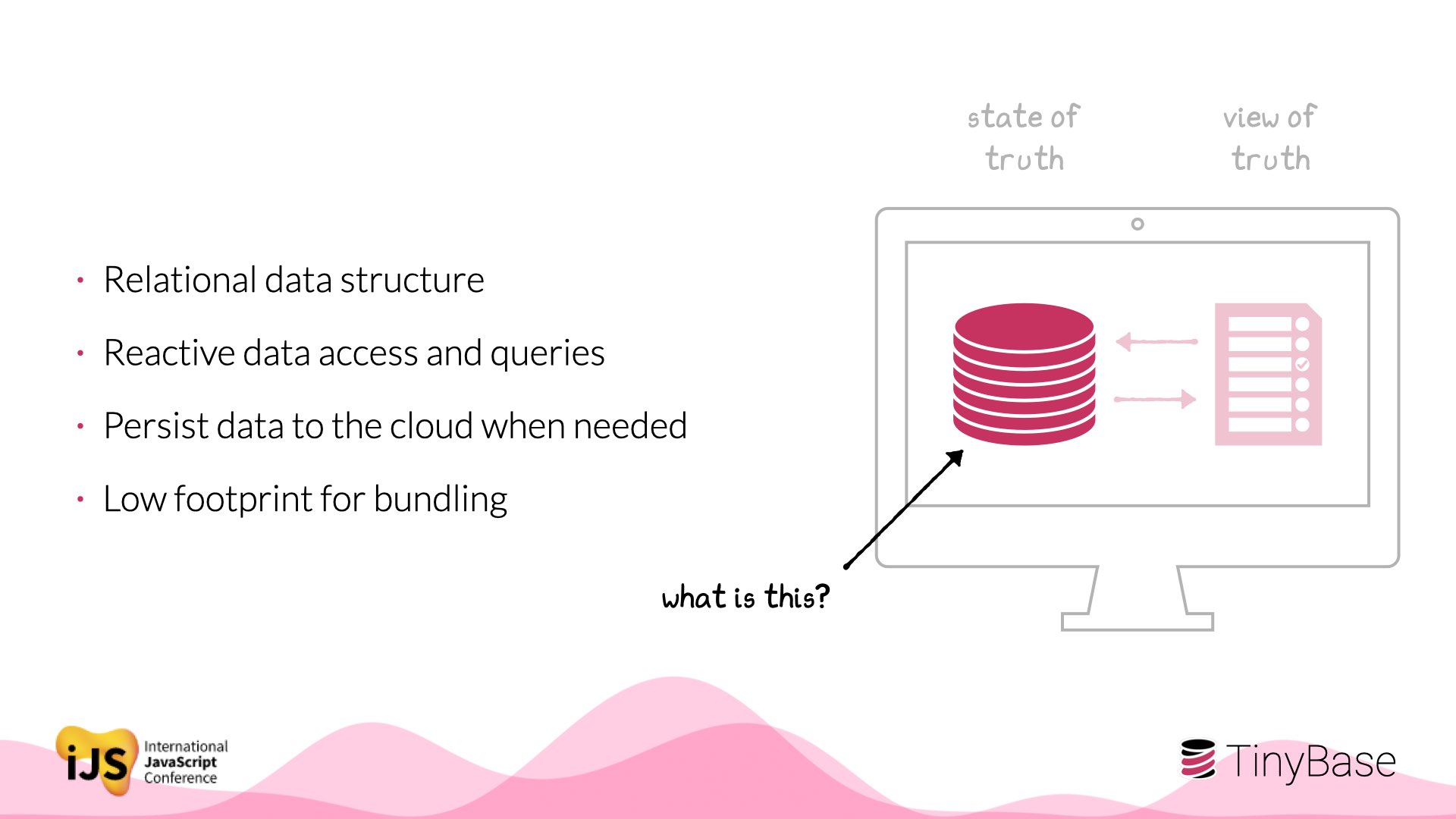
So what is this thing? It has these 4 requirements. But meeting them all is tricky!
Some state management tools provide reactivity but not structure - or assume a cloud-first app. On the other hand, a fully-fledged RDBMS likely compromises reactivity or footprint.

So it seems like local-first apps on the web might be a bit of a struggle.
With these challenges in mind, I’ve been building a project called TinyBase. It explores these ideas and tries to meet these requirements without too many trade-offs.

The zeroth thing about TinyBase is probably a bit meta until you know what the library does - but I wanted to get it out there anyway.
The clue is in the name - but yes, TinyBase is tiny!

Remember when the Ever Given got stuck in the Suez Canal last year?
This little digger trying to free a monstrous ship is the perfect metaphor for the life of a modern JavaScript developer. Why is my simple app bundle suddenly 6Mb bigger than it was the day before?

I wanted to do my bit. TinyBase has no external dependencies. This is pretty rare for non-trivial libraries.
You get core functionality for 4Kb (compressed), or everything for 8Kb. You can also reason about its (empty!) supply chain and security risks.
And I should say that keeping a JS library tiny takes a special type of obsession.
As a brief aside, I wrote about the experience of building a personal project without the typical constraints or deadlines of a professional environment. It’s been really interesting.

Back to TinyBase. One distinguishing feature is that it requires you to store your app state in a tabular structure.
Uniquely named tables, containing uniquely name rows, containing uniquely named cells, containing strings, booleans, and numbers. That’s it.
This might seem quite limiting, but unlike a real RDBMS, schemas are optional. Each row can have different cells to the others, so you can store orthogonal flat objects in each row. You can fit a lot of concepts into nested three-level tabular structures.
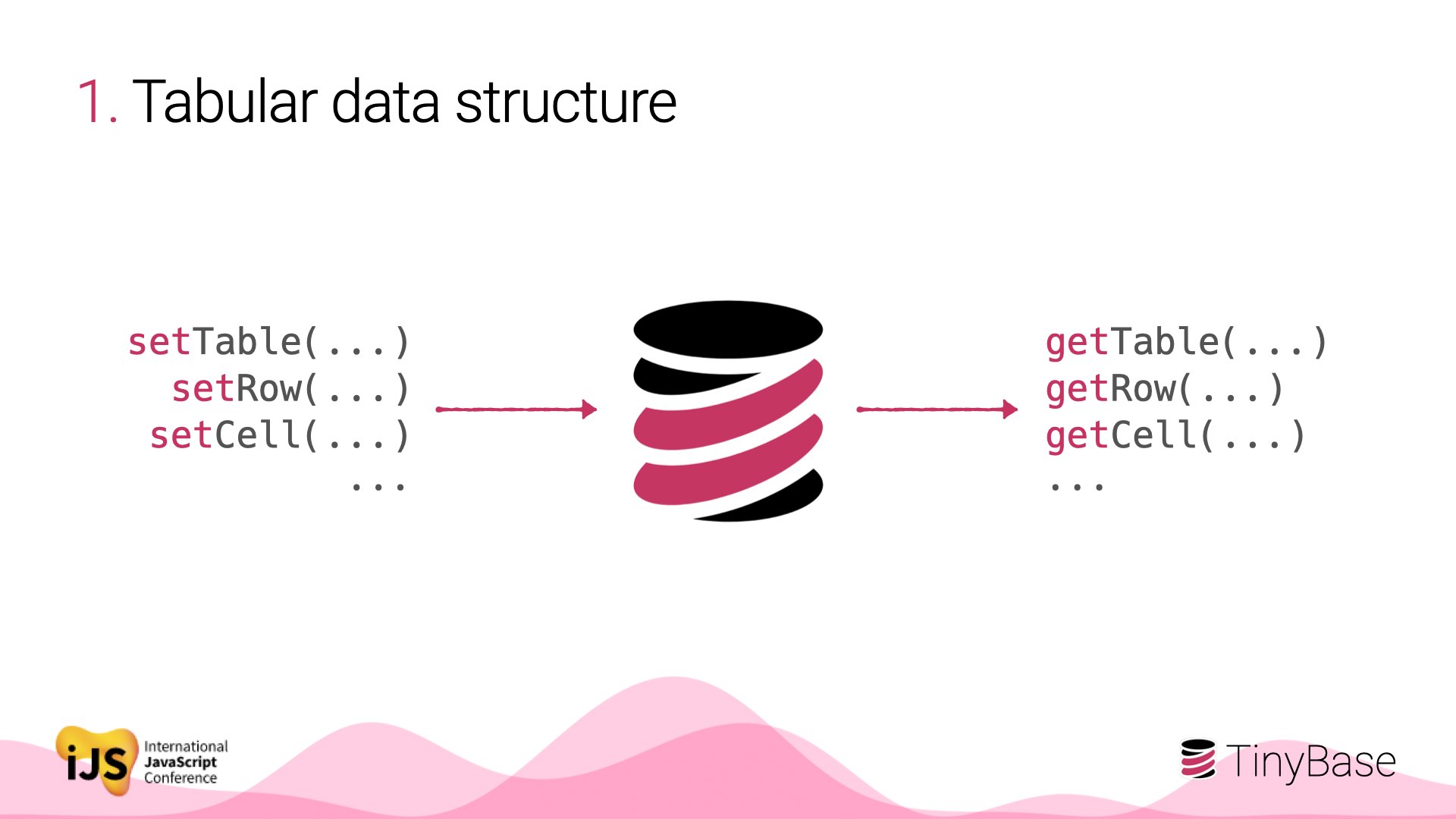
To work with that structure of data, there’s a completely obvious API for setting and getting data in an out of the store. Set tables, rows, and cells, and then read them back out.
OK, so I know what you’re thinking. This is maybe not so very interesting yet.
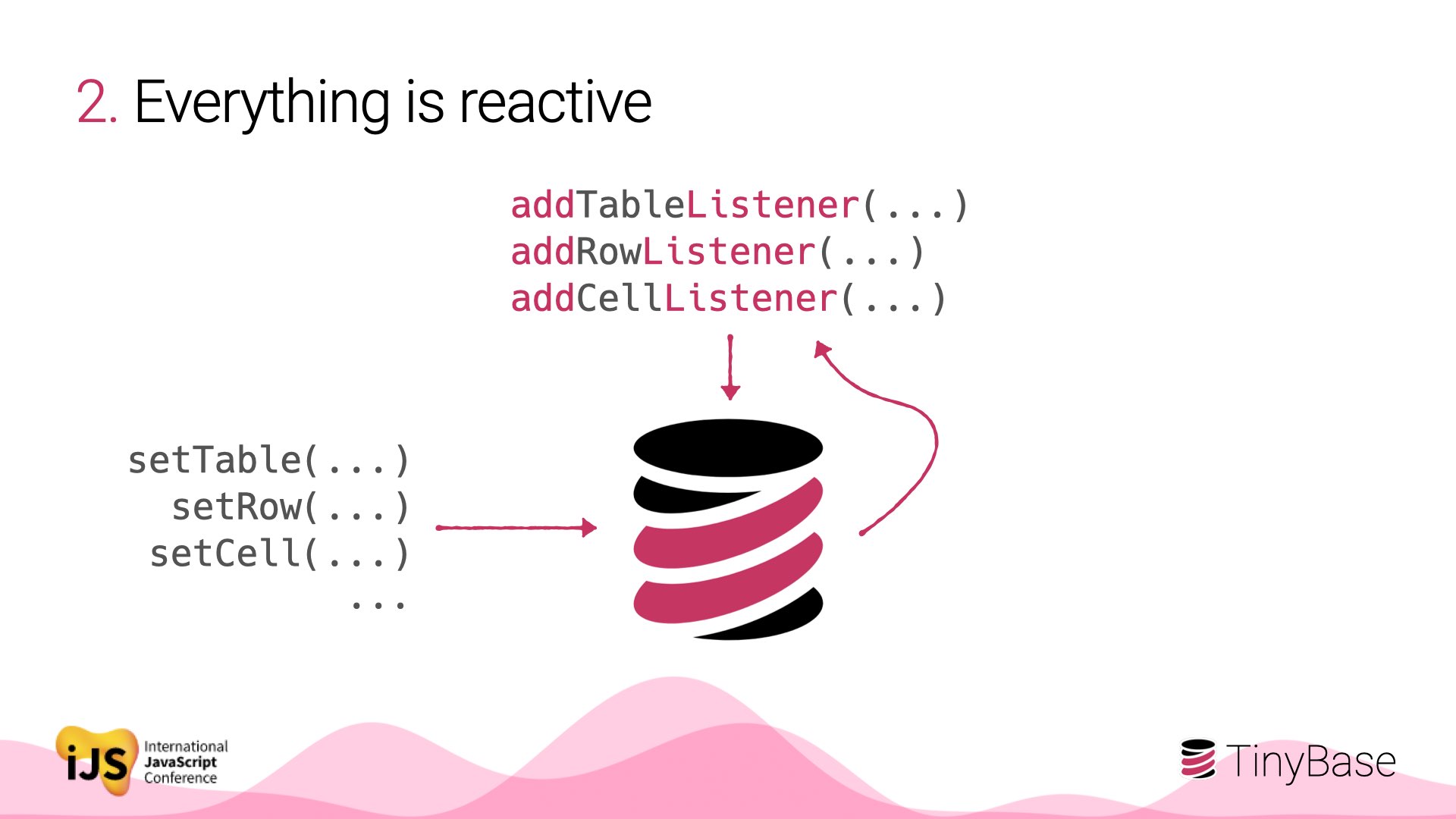
But an opinionated data structure can be reactive. Changes to any part of a TinyBase store can be listened for, and at any granularity.
Register a listener in one part of your app, and if another part makes changes to the relevant state, you’ll get a callback immediately.
And there are all the propagations and cascades you would expect here. Changing a cell will fire a listener for the table it’s in. Changing a whole table table will fire any listeners for the affected cells within - and so on.
But only those parts that change! TinyBase won’t waste your app’s cycles with parts of the data that stay the same. This is one of the reasons you can only store strings, booleans and numbers in each cell - they’re fast and easy to check for equality.
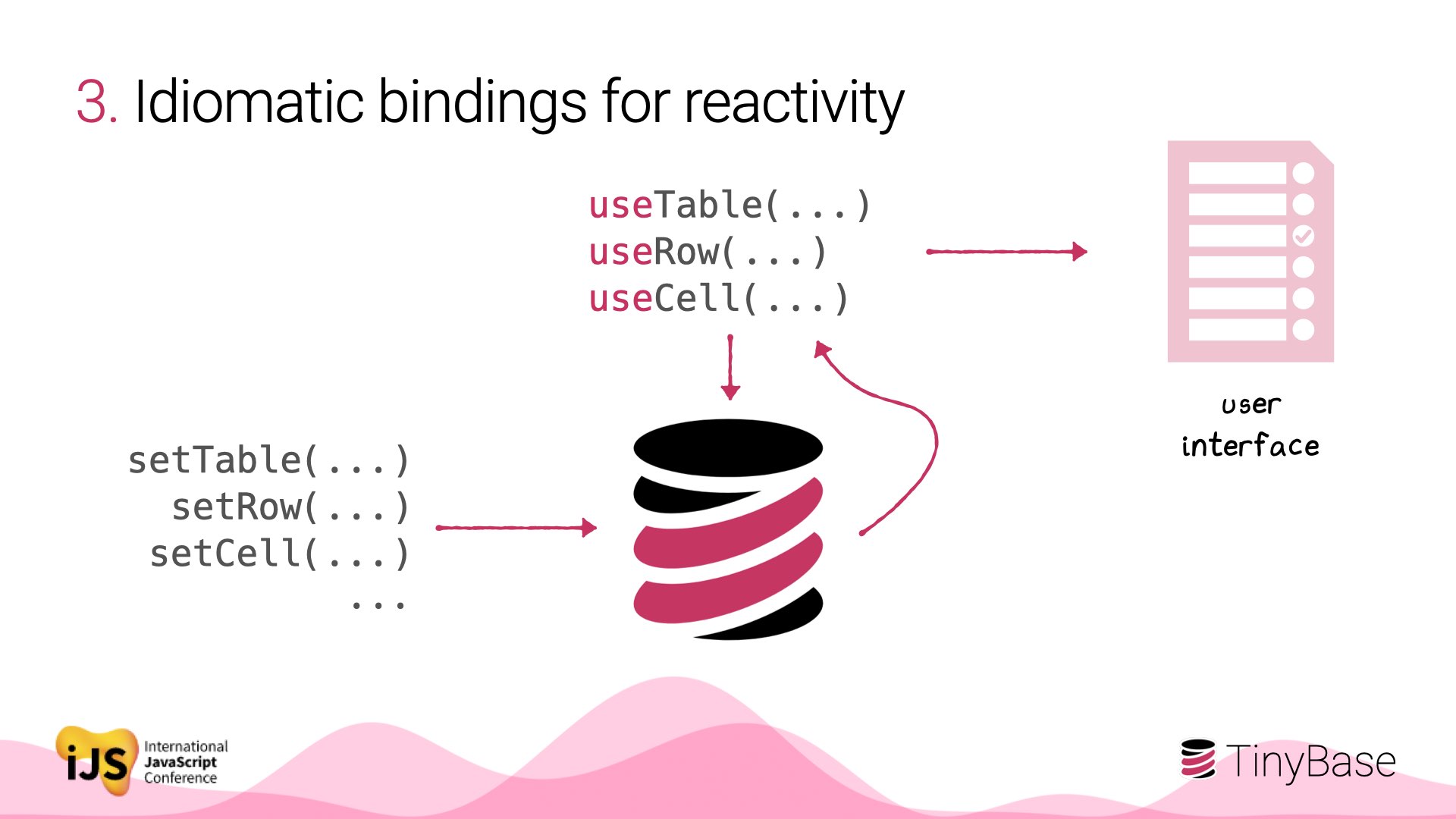
TinyBase doesn’t require React, but if you do use it, optional idiomatic bindings are available.
This is where the reactivity really pays off. The React hooks set up listeners, and only cause the component to re-render when the underlying data changes.
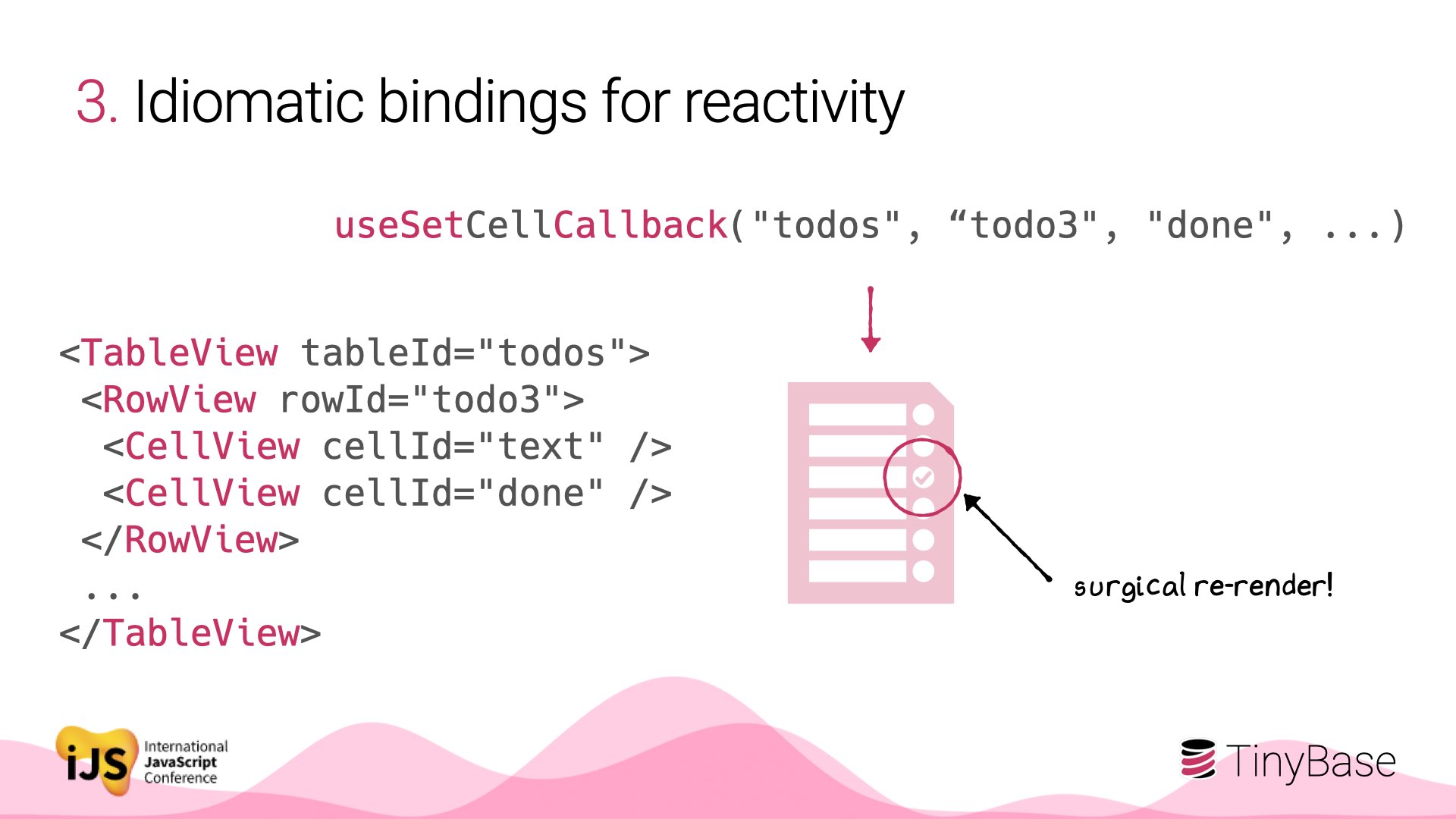
Imagine you have a todo app: a table of rows, with text and ‘done’ flag for each. (The JSX syntax here is illustrative).
Click the flag, and the data is immediately stored. The change then fires an event to update just the component for that cell: a surgical re-render.
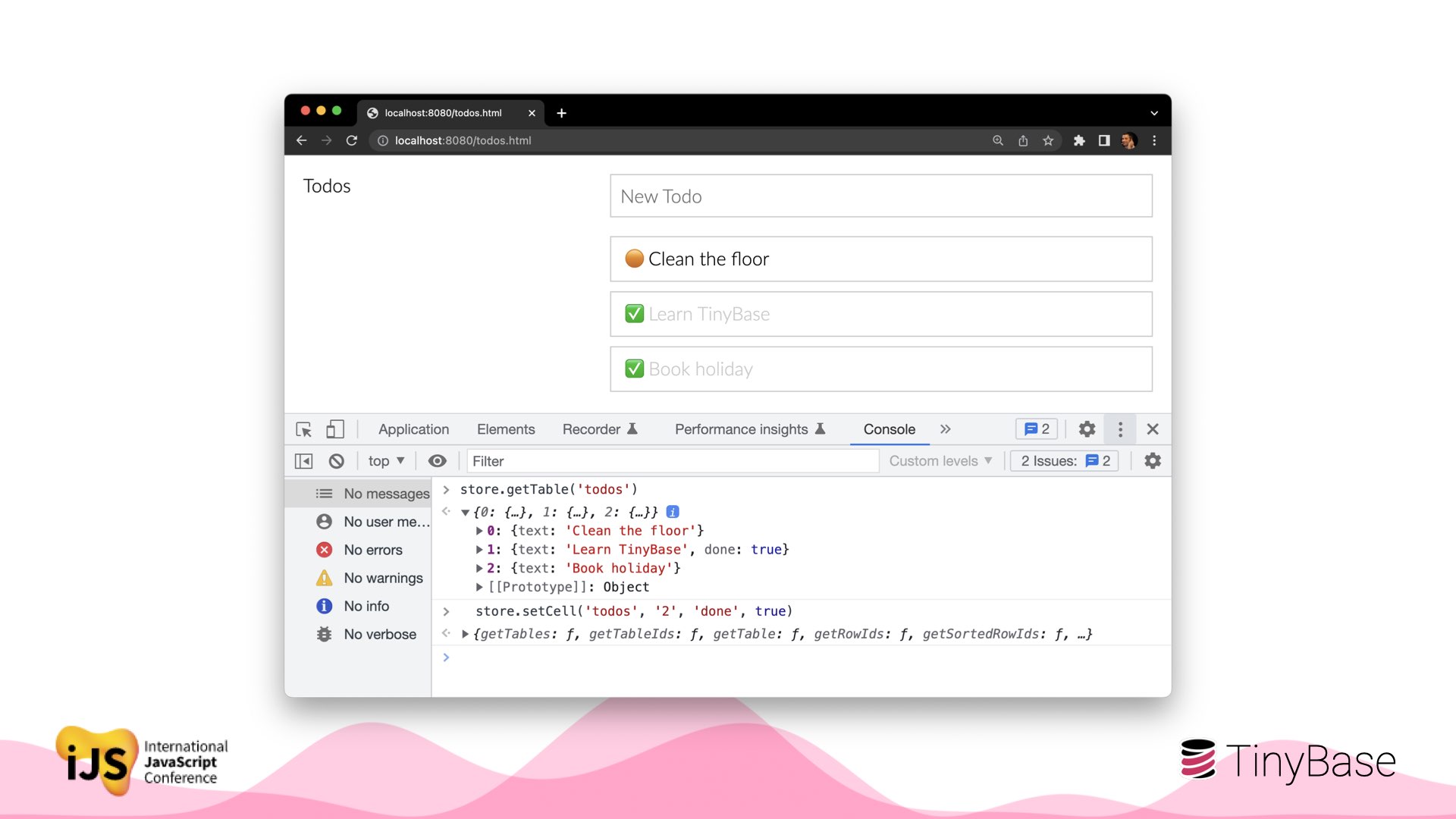
Here’s a demo. The store has just three rows, with text and done cells.
The moment we change the data, the UI updates - and as you can see, only the row that changed re-renders.
Suffice to say that if this was coming from a server source of truth we would naively have to send an update to the server, perhaps even re-querying the whole table over the wire and re-rendering it all.

Whilst not a fully featured RDBMS, TinyBase does support some of the things that you typically do with such a system:
- metrics of aggregated numeric values
- indexes to look up rows quickly
- relationships to associate rows to each other
These are also all reactive!
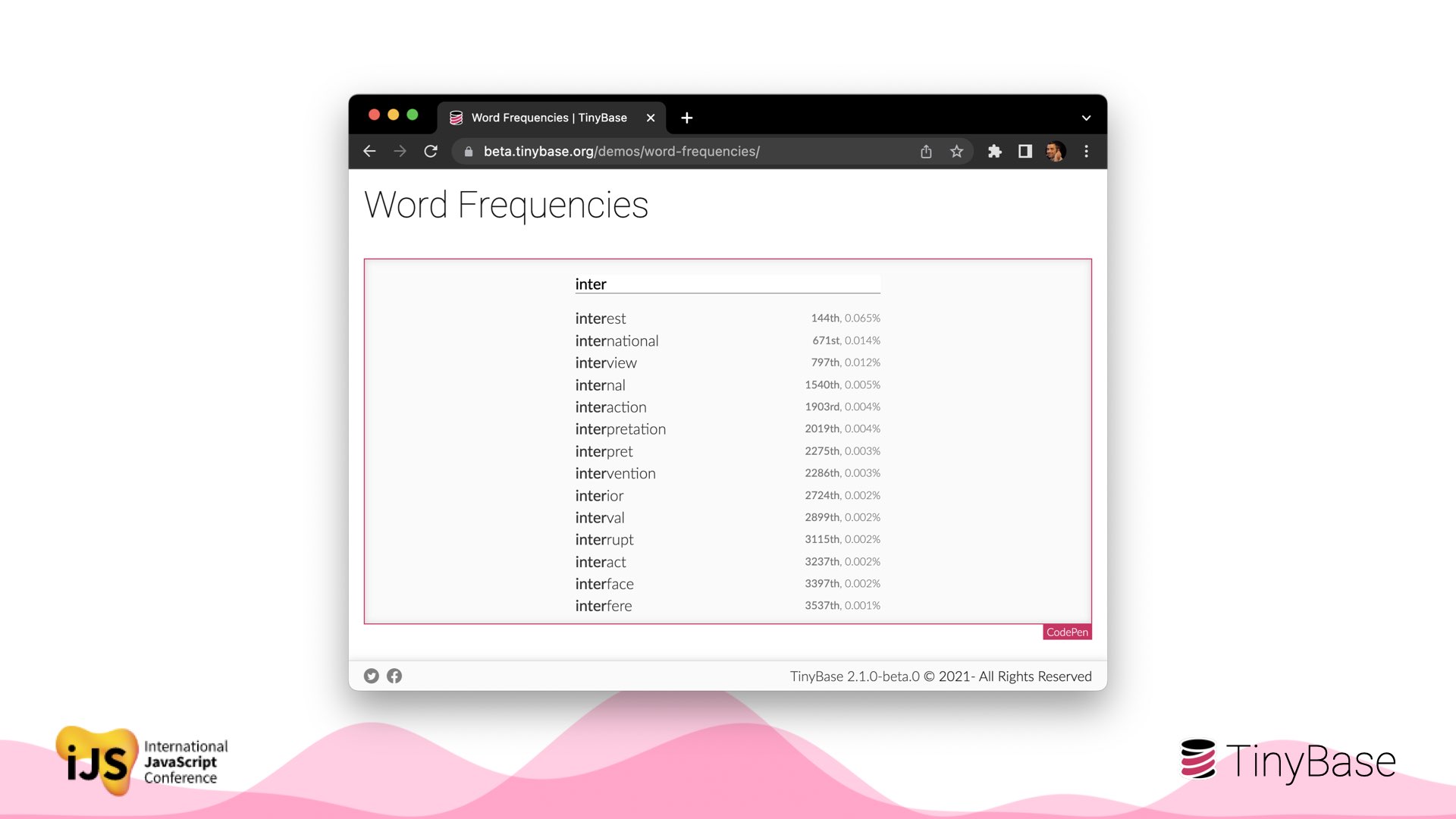
This demo indexes 10,000 words by stem, for a prefix-based autocomplete.
You get an idea of how fast local-first can be. Imagine the spinners if you loaded a new list of words from a server every time you pressed a key.
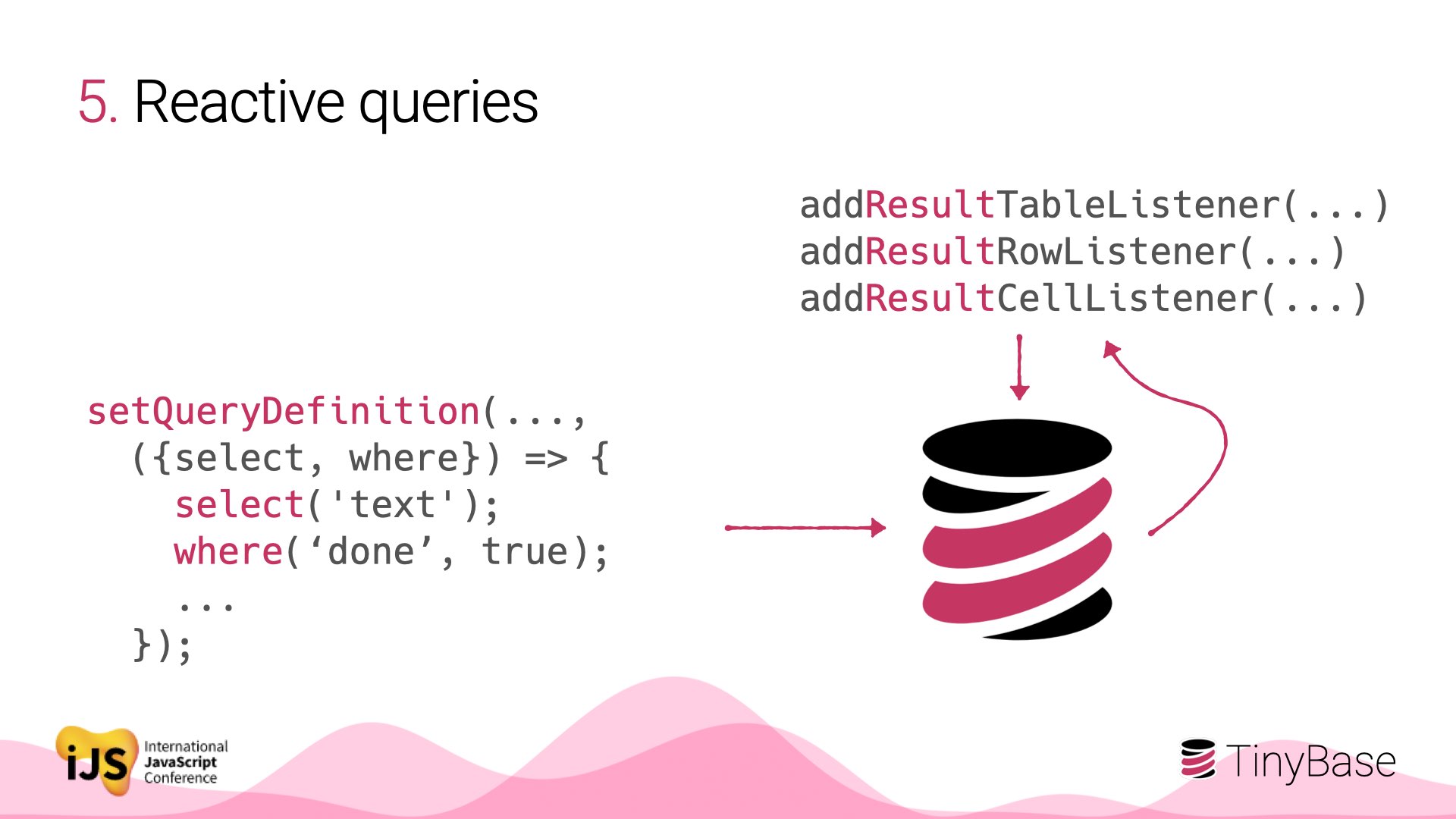
You can even express SQL-like queries (select, where, join, group-by, etc) with an imperative dialect called TinyQL, and register listeners to render the results - again reactively.
This is new, but opens up interesting ideas for client-side analytics and rich data-driven apps.

Here’s an example of how we build up a query with TinyQL. It’s got two tables: pets and owners. And then we set the definition to select the species of the pet, and the name of the owner. The reactive results are just as you would expect.

Here’s a more complex example with 5 tables and relational IDs to connect them.
One thing that’s notable: because this is imperative rather than declarative SQL, the joins are all made in a programmatic loop.
That’s TinyQL. Excited to see how people use this.
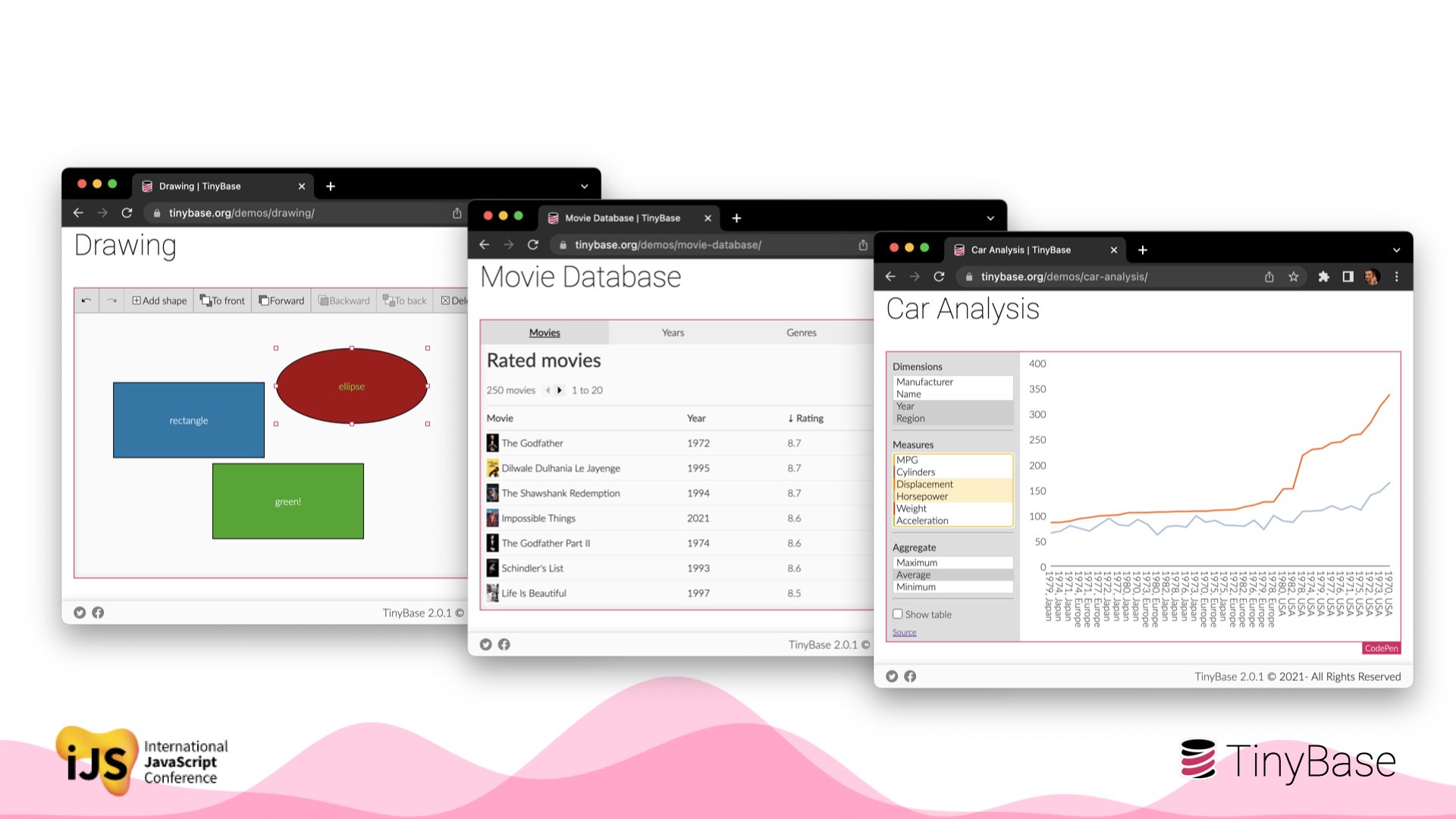
Here are a few other demo apps that showcase the benefits of using a local-first architecture:

There’s more to TinyBase of course. It turns out 8kb can get you a lot these days.
Next I’ll be adding typed ORM APIs so you can start modeling your domain in TypeScript.
And CRDT synchronization is a stretch goal. It’ll be truly local-first if I can pull that off!

Let’s pop back up the stack to summarize what we’ve talked about.
Firstly, we talked about local-first apps. There is an alternative to having everything locked up in a cloud, and placing more of the logic and content of truth on a client device.

More fine reading: I greatly recommend this article by @inkandswitch.
They talk about a set of seven principles for local-first apps, of which this is just one.
These are all wonderful food for thought.
We also talked about what this means architecturally - bringing a relational, reactive data store into the client, rather than having that source of truth in the cloud.
And we looked at how TinyBase might be an interesting way to do that.

I must stress that your mileage may vary. This is no panacea.
Certain types of apps can never be local-first: a social network or a banking app, to name just two! And until decentralized synchronization is more widespread, the cloud is still pivotal for collaboration.
I also think it’s not always super easy to retrofit a local-first architecture onto an app that’s already cloud-first - at least compared to going local-first in a more greenfield environment from the start.

But I feel like if you can make local-first work, you should give it a try.
This morning’s beautiful sunrise is symbolic, because it’s easy for us to get stuck in the status quo, following established approaches even when constraints change and opportunities arise.

If you’re here, you are still early in thinking about local-first apps.
And if we can pioneer new techniques that help us build more amazing user experiences (and yes, question a few assumptions along the way) - we should do it, and together!
Thank you.